XTask: eXTreme fine-grAined concurrent taSK invocation runtime
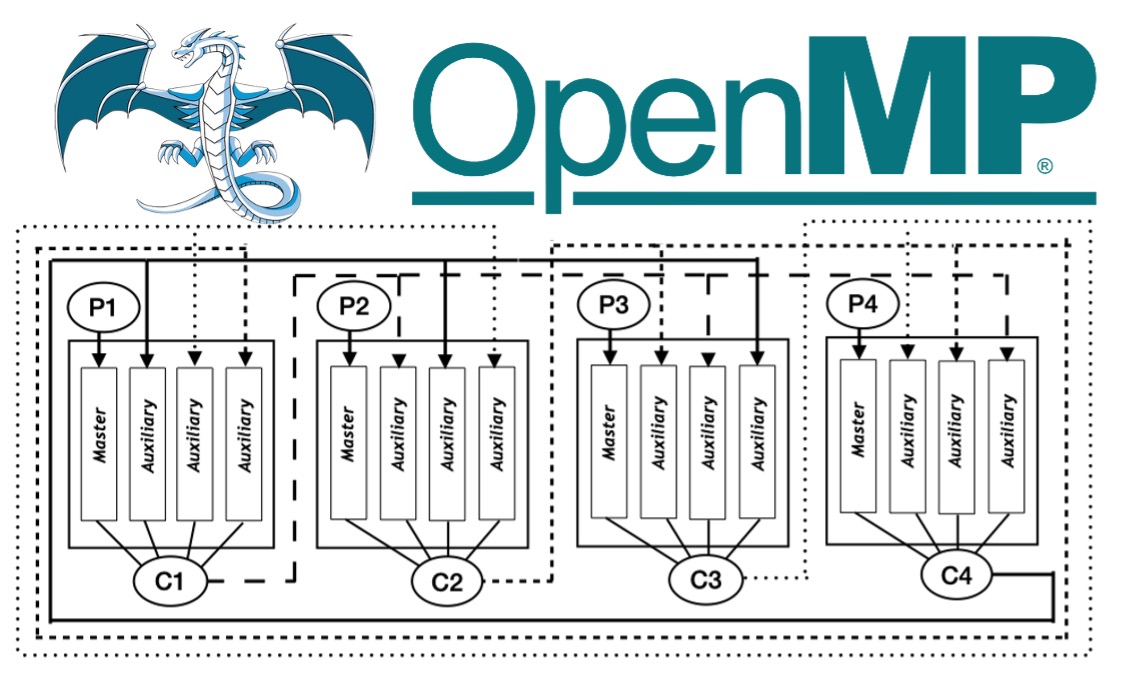 Processors with 100s of threads of execution and GPUs with 1000s of cores are among the state-of-the-art in high-end computing systems. This transition to many-core computing has required the community to develop new algorithms to overcome significant latency bottlenecks through massive concurrency. Implementing efficient parallel runtimes that can scale up to hundreds of threads with extremely fine-grained tasks (less than 100μs) remains a challenge. We proposed XQueue, a novel lockless concurrent queueing system that can scale up to hundreds of threads. We integrate XQueue into LLVM OpenMP and implement X-OpenMP, a library for lightweight tasking on modern many-core systems with hundreds of cores. We show that it is possible to implement a parallel execution model using lock-less techniques for enabling applications to strongly scale on many-core architectures. We extend our work to include dynamic load balancing using work stealing to efficiently distributes the load across worker threads. We implement a lock-less algorithm for work stealing and evaluate the performance using micro and macro benchmarks. We compare the performance of X-OpenMP with native LLVM OpenMP and GNU OpenMP implementations using task-based linear algebra routines from PLASMA numerical library, Strassen's matrix multiplication from the BOTS Benchmark Suite, and the Unbalanced Tree Search benchmark. Applications parallelized using OpenMP can run without modification by simply linking against the X-OpenMP library. X-OpenMP achieves up to 40X speedup compared to GNU OpenMP and up to 6X speedup compared to the native LLVM OpenMP implementations on fine-grained parallel workloads.
Processors with 100s of threads of execution and GPUs with 1000s of cores are among the state-of-the-art in high-end computing systems. This transition to many-core computing has required the community to develop new algorithms to overcome significant latency bottlenecks through massive concurrency. Implementing efficient parallel runtimes that can scale up to hundreds of threads with extremely fine-grained tasks (less than 100μs) remains a challenge. We proposed XQueue, a novel lockless concurrent queueing system that can scale up to hundreds of threads. We integrate XQueue into LLVM OpenMP and implement X-OpenMP, a library for lightweight tasking on modern many-core systems with hundreds of cores. We show that it is possible to implement a parallel execution model using lock-less techniques for enabling applications to strongly scale on many-core architectures. We extend our work to include dynamic load balancing using work stealing to efficiently distributes the load across worker threads. We implement a lock-less algorithm for work stealing and evaluate the performance using micro and macro benchmarks. We compare the performance of X-OpenMP with native LLVM OpenMP and GNU OpenMP implementations using task-based linear algebra routines from PLASMA numerical library, Strassen's matrix multiplication from the BOTS Benchmark Suite, and the Unbalanced Tree Search benchmark. Applications parallelized using OpenMP can run without modification by simply linking against the X-OpenMP library. X-OpenMP achieves up to 40X speedup compared to GNU OpenMP and up to 6X speedup compared to the native LLVM OpenMP implementations on fine-grained parallel workloads.
-
Period: 01/2016 - Present
-
Languages: C/C++, Python
-
Features: TBA
-
Technologies: TBA
-
OS: Linux
-
Testbeds: Mystic, Chameleon
-
Scalability: TBA
-
Performance: TBA
-
Funding: NSF
Publications
- Poornima Nookala, Kyle Chard, and Ioan Raicu. “X-OpenMP – eXtreme fine-grained tasking using lock-less work stealing”, under review at IEEE Transactions on Parallel and Distributed Systems (TPDS)
- Poornima Nookala, Peter Dinda, Kyle C. Hale, Kyle Chard, and Ioan Raicu. “XQueue - A Lock-less Queueing Mechanism for Task-Parallel Runtime Systems”, under review at IEEE Transactions on Emerging Topics in Computing (TETC)
- Poornima Nookala, Ioan Raicu. "Extreme Fine-grained Parallelism on Modern Many-Core Architectures", Illinois Institute of Technology, Computer Science Department, Doctorate Dissertation, December 2022
- Poornima Nookala, Ioan Raicu. "Exploring Extreme Fine-grained Parallelism on Modern Many-Core Architectures", Illinois Institute of Technology, Computer Science Department, PhD Proposal, May 2022
-
Poornima Nookala, Peter Dinda, Kyle Hale, Ioan Raicu and Kyle Chard. "Enabling Extremely Fine-grained Parallelism via Scalable Concurrent Queues on Modern Many-core Architectures", Proceedings of the 28th IEEE International Symposium on the Modeling, Analysis, and Simulation of Computer and Telecommunication Systems (MASCOTS ‘21) 2021
-
Poornima Nookala, Peter Dinda, Kyle Hale, Ioan Raicu. “XTASK - eXTreme fine-grAined concurrent taSK invocation runtime”, Illinois Institute of Technology, Department of Computer Science, PhD Oral Qualifier, 2017
-
Pedro Valero-Lara, Poornima Nookala, Fernando L. Pelayo, Johan Jansson, Serapheim Dimitropoulos, Ioan Raicu. "Many-Task Computing on Many-Core Architectures," Special Issue on High Performance Computing Solutions for Complex Problems, Scientific International Journal for Parallel and Distributed Computing, Scalable Computing: Practice and Experience, 2016
-
Thomas Dubucq, Tony Forlini, Virgile Landeiro Dos Reis, Isabelle Santos, Ke Wang, Ioan Raicu. “Benchmarking State-of-the-art Many-Task Computing Runtime Systems”, ACM HPDC 2015
-
Poornima Nookala, Serapheim Dimitropoulos, Karl Stough, Ioan Raicu. "Evaluating the Support of MTC Applications on Intel Xeon Phi Many-Core Accelerators", IEEE Cluster 2015
-
Scott Krieder, Ioan Raicu, Justin Wozniak, Michael Wilde. "Implicitly-Parallel Functional Dataflow for Productive Cloud Programming on Chameleon", NSFCloud Workshop on Experimental Support for Cloud Computing 2014
-
Scott J. Krieder, Justin M. Wozniak, Timothy Armstrong, Michael Wilde, Daniel S. Katz, Benjamin Grimmer, Ian T. Foster, Ioan Raicu. “Design and Evaluation of the GeMTC Framework for GPU-enabled Many-Task Computing”, ACM HPDC 2014; 16% acceptance rate
-
Benjamin Grimmer, Scott Krieder, Ioan Raicu. "Enabling Dynamic Memory Management Support for MTC on NVIDIA GPUs", EuroSys 2013 (poster)
-
Scott Krieder, Ioan Raicu. "GEMTC: GPU Enabled Many-Task Computing", Illinois Institute of Technology, Department of Computer Science, PhD Oral Qualifier, 2013
-
Scott Krieder, Ioan Raicu. “Towards the Support for Many-Task Computing on Many-Core Computing Platforms”, Doctoral Showcase, IEEE/ACM Supercomputing/SC 2012 (poster)
-
Scott Krieder, Ben Grimmer, Ioan Raicu. “Early Experiences in running Many-Task Computing workloads on GPGPUs”, XSEDE 2012 (poster)
Presentation
- TBA